6. Februar 2026 · Artikel
Everything is Context-Engineering: Die Systematik hinter reproduzierbaren LLM-Outputs
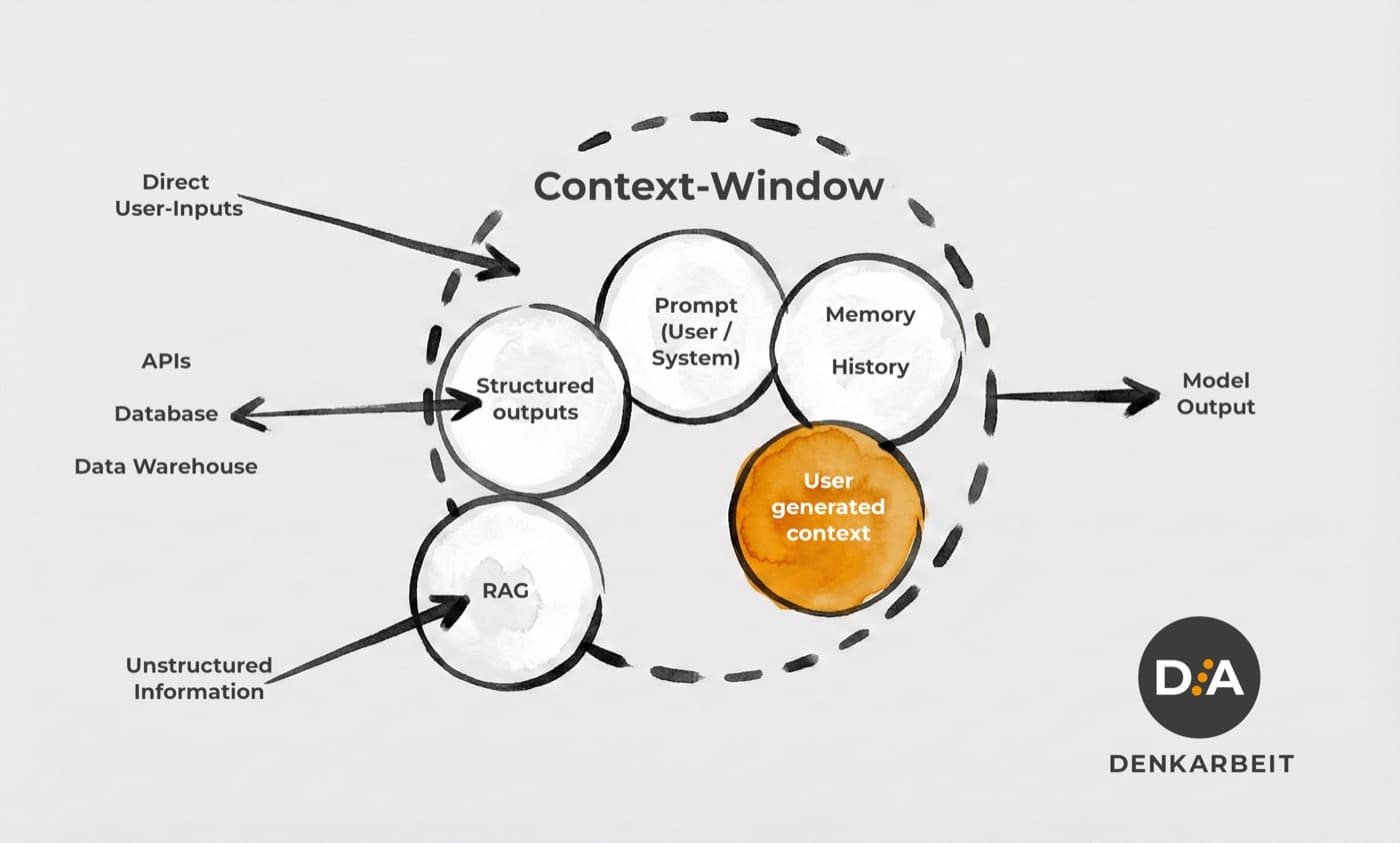
Context-Engineering bildet einen fundamentalen Denkrahmen, um die Funktionsweise von Large Language Models (LLMs) zu erfassen und deren Ergebnisse verlässlich zu gestalten. Während spezialisierte Anwender in der Softwareentwicklung oder bei der Konzeption autonomer Agenten diese Prinzipien als notwendige Basis ansehen, bleibt das Potenzial in der alltäglichen Anwendung oft ungenutzt. Die Resultate eines Modells sind keine Zufallsprodukte, sondern die unmittelbare Konsequenz der verschiedenen Inputs.
Gutes Context-Engineering bedeutet, sämtliche Eingabeformen als möglichst kohärentes und spezifisches Gesamtes zu denken. Vier kritische Aspekte stehen dabei im Fokus:
- Die Identifikation der für den gewünschten Output zwingend erforderlichen Informationen.
- Form und Qualität der vorhandenen Informationen.
- Notwendige, aber nicht vorhandene Informationen.
- Die Steuerung der statistischen Aufmerksamkeit des Modells durch dessen Datenraum (Vermeidung von Drift und Halluzination).
Context-Engineering beinhaltet zudem eine ökonomische Optimierung: Jedes Token beansprucht Rechenkapazität, verursacht Kosten und beeinflusst bei übermäßiger Auslastung die Präzision des Modells.
Kapazitätsgrenzen: Context Window und 40-Prozent-Regel
Jede Interaktion mit einem LLM erfolgt aus dessen Sicht innerhalb eines definierten Raums: dem Context Window. Dieses legt die maximale Informationsmenge fest, die das Modell in einem einzigen Rechenschritt verarbeiten kann. Die Messung erfolgt in Token, den kleinsten semantischen Einheiten. Als Orientierung gilt: 1.000 Token entsprechen im Deutschen circa 600 bis 700 Wörtern.
Die technischen Kapazitäten der bekanntesten LLMs im Jahr 2026 sind:
- GPT-5: ca. 256.000 Token.
- Claude 4: ca. 500.000 Token.
- Gemini 3: Bis zu 1 Million Token.
Die schiere Dimension dieser Fenster ist jedoch trügerisch. Es tritt ein Phänomen auf, das als Kontext-Degradierung (Context Rot) bezeichnet wird. LLMs basieren auf der Transformer-Architektur, das heißt, jedes Token setzt eine mathematische Beziehung zu jedem anderen Token innerhalb des Fensters. Mit zunehmender Auslastung leidet das Aufmerksamkeitsbudget des Modells. Die Präzision beim Abruf von Informationen oder die Aufrechterhaltung komplexer logischer Ketten über weite Distanzen nimmt ab.
Die Abrufgenauigkeit und korrekte logische Verknüpfung können signifikant abnehmen, sobald das Context Window zu mehr als 40 Prozent belegt ist. Diesen Zustand nennt man auch „Dumb Zone“; für geschäftskritische Prozesse markiert dies die Grenze der Verlässlichkeit. Context-Engineering erfordert hier eine strikte Priorisierung, den Einsatz von Techniken wie der Compaction sowie die rechtzeitige Bereinigung oder den Start einer neuen Sitzung.
Rollenarchitektur: Präzise Steuerung der Aufmerksamkeit
Die gezielte Lenkung der Modellaufmerksamkeit erfordert ein fundiertes Verständnis über die Platzierung spezifischer Informationen innerhalb der technischen Architektur. In den Benutzeroberflächen moderner KI-Systeme sowie in deren Programmierschnittstellen (APIs) sind diese Rollen funktional getrennt: System-Prompt, User-Prompt und Model-Output.
1. System – Der System-Prompt definiert den Lösungsraum und fungiert als fundamentale strukturelle Vorgabe. In gängigen Chat-Anwendungen findet sich diese Funktion oft unter Bezeichnungen wie „System-Anweisungen“ oder „Custom Instructions“. Technisch betrachtet verengt der System-Prompt die Optionen der Generierung auf eine spezifische Persona sowie auf festgesetzte Regeln und Restriktionen.
2. User – Die User-Rolle liefert den finalen Impuls für die Generierung. Entgegen der häufigen Annahme umfasst der User-Prompt weit mehr als nur die manuelle Eingabe. Der effektive Input setzt sich oft aus der Chateingabe und automatisiert injizierten Daten zusammen. Hinterlegt ein User Dateien oder verknüpft er eine Quelle, findet im Hintergrund eine Retrieval Augmented Generation (RAG) statt.
3. Model – Die Rolle „Model“ (oder „Assistant“) umfasst sämtliche Antworten, die das System innerhalb der laufenden Session bereits generiert hat. LLMs operieren grundsätzlich zustandslos. Falls das Modell zuvor fehlerhafte Informationen ausgegeben hat, wirken auch diese als Referenzpunkte, die zukünftige Resultate negativ beeinflussen können.
Funktionserweiterung: Tools und strukturierte Daten
Moderne Systeme erweitern ihren Kontext zusätzlich durch spezialisierte Mechanismen:
- Retrieval Augmented Generation (RAG): Reichert den Prompt dynamisch mit Daten an, die durch einen semantischen Abgleich aus einer verknüpften Quelle extrahiert werden.
- Structured Outputs: Definieren das Zielformat der Antwort, beispielsweise als JSON-Objekt. Entscheidend, wenn Ergebnisse unmittelbar durch andere Applikationen weiterverarbeitet werden sollen.
- Multimodalität: Visuelle Daten bieten eine hohe kontextuelle Dichte und wirken oft präziser als umfangreiche textliche Beschreibungen.
Full Context vs. RAG
Full Context Loading bedeutet die direkte Integration aller relevanten Daten in den Prompt. Dies gewährleistet maximale Kohärenz, da das Modell simultanen Zugriff auf alle Informationen besitzt. RAG stellt hingegen die Lösung für umfangreiche Wissensbestände dar – es fungiert als automatisierter Selektionsprozess, der ausschließlich die relevantesten Informationen extrahiert.
Trotz der Skalierbarkeit stößt RAG an systemische Grenzen:
- Redundanz und Widersprüche: Der Selektionsalgorithmus kann bei mehreren Versionen derselben Information nicht zuverlässig entscheiden, welche korrekt ist.
- Kontext-Fragmentierung: Da Dokumente in kleine Einheiten zerlegt werden, geht oft der Blick für das Große Ganze verloren.
- Semantisches Rauschen: Bei unstrukturierten Datenräumen sinkt die Trefferquote.
Wissensgrenzen: Dokumentationskultur als Flaschenhals
Context-Engineering macht Defizite in der internen Dokumentationskultur deutlich. Ein System kann ausschließlich Informationen verarbeiten, die explizit vorliegen. Eine große Herausforderung ist implizites Wissen – Informationen, die vorausgesetzt, aber nicht schriftlich fixiert sind. Context-Engineering ist damit auch ein Auftrag an Organisationen, über ihr Wissensmanagement strategisch nachzudenken.
Datenhygiene: Pruning und Compaction
Professionelles Context-Engineering versucht, die Relevanz aller Inputs zu optimieren. Kernprinzipien:
- Fokus auf High-Signal-Tokens: Jedes Zeichen beansprucht Teile des limitierten Aufmerksamkeitsbudgets. Überflüssige Details fördern kein tieferes Verständnis, sondern führen zur Interferenz.
- Struktur und Kohärenz: Guter Kontext ist semantisch widerspruchsfrei. Textformate wie Markdown sind hilfreich, weil sie zusätzliche Strukturierung liefern.
Zur Rückgewinnung der logischen Schärfe empfehlen sich zwei Strategien:
- Pruning: Die gezielte Reduktion von Daten – Entfernen veralteter Dateianhänge, Löschen redundanter Zwischenergebnisse.
- Compaction: Die intelligente Verdichtung von Informationen. Das Modell fasst die Essenz der Ergebnisse in einem kompakten Status-Update zusammen, mit dem eine neue Sitzung initiiert wird.
Fazit: Vom Prompting zum Context-Management
Context-Engineering ist die Optimierung von LLM-Outputs anhand der Inputs. Bei einfachen Aufgaben ist dies trivial. Doch die Beobachtung, dass in einem langen Chat-Verlauf die Output-Qualität irgendwann deutlich abnimmt, werden auch die meisten Alltagsnutzer schon gemacht haben. Als Denkrahmen hilft Context-Engineering, das Verhalten von Sprachmodellen zu interpretieren und gezielt zu beeinflussen.
Naheliegend ist, LLMs selbst für die Erstellung und Pflege von Kontext einzusetzen. Context-Engineering ist auch die ständige Verkettung von In- und Outputs. Bis der Mensch sich ein Kontext-Perpetuum-Mobile erschaffen hat, bleibt die entscheidende Frage: Welchen Input muss und will er selbst geben?